Amelie works over HTTP and does not require additional client libraries or compatibility with other databases. It can be used directly with any modern programming language or tooling that supports HTTP and JSON.
Distributed as a single executable file, which provides the functionality of the Database Server, Console Client, and Benchmark tool.
The project is in public Beta. All its features have been tested and documented.
We are happy to provide help and professional support. If you have questions or ideas, feel something is missing, not working as you think it should, or have issues, please get in touch with us using the community Slack or GitHub.
The short list of features:
- Serializable ACID Multi-statement transactions
- Secondary indexes (Tree/Hash)
- CTE with DML RETURNING
- Parallel partitioned DML including UPSERT
- Parallel JOINs
- Parallel GROUP BY and ORDER BY
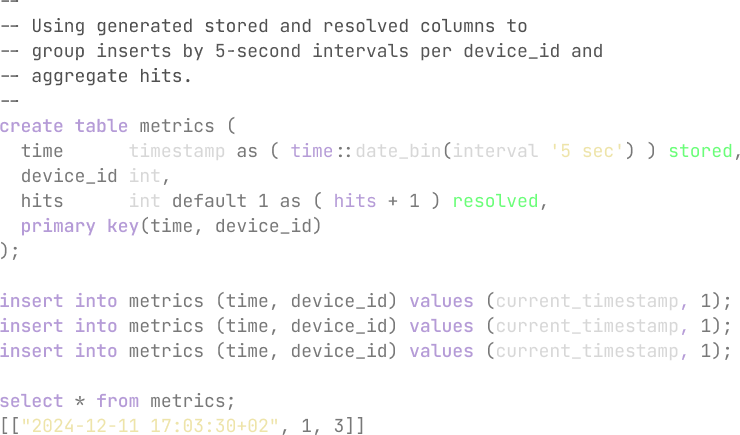
- Partitioned Generated Columns
- Native VECTOR support
- Native JSON support
- Parallel snapshotting and recovery
- Hot Remote Backup
- Asynchronous Logical Replication
- HTTP API
Revisiting common architectural bottlenecks such as lock contentions, IO processing, and the necessity for multi-versioning, we wanted to create a database that does things differently for most use cases involving short transactions.
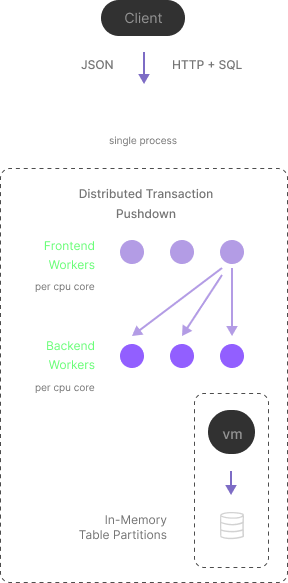
The main idea is to treat CPU cores like distributed databases treat their remote nodes and apply similar logic for a tight single-process multi-core processing system that scales IO and Compute independently.
While having a distributed database design, Amelie does not require the complex maintenance typical of distributed systems and works as a single process, hiding all the complexity.
Amelie has two independent processing levels for IO and Compute — Frontend and Backend processing.
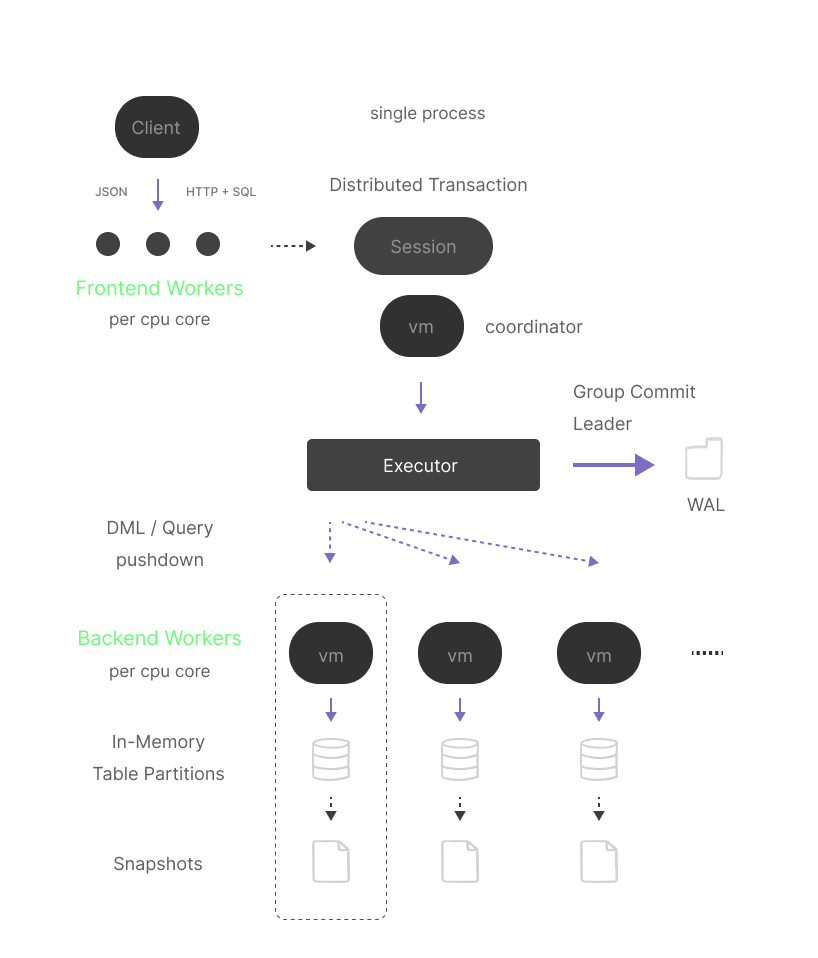
The current implementation does not support network-distributed transactions — all distributed transactions are local and executed as part of a single process involving backend worker threads.
It separates IO, HTTP/TLS, SQL parsing, Bytecode compilation, and distributed transaction execution coordination from actual data access and modification.
Increasing the worker’s pool size allows the database to serve more clients and increases throughput.
Compared to the thread-per-connection approach, it significantly scales processing throughput for short transactions by reducing the number of context switches for multiple connections, allowing more useful work.
A backend worker thread is designed to run in a tight loop with the Executor, sharing a single WAL. Each worker has an associated list of table partitions, which it can access individually without interfering with other workers. Each partition modification is done using the local transaction context.
The worker executes incoming requests in a strict order driven by the Executor. Each request consists of a bytecode explicitly generated for this worker to be executed by its virtual machine context.
Backend workers can be created or dropped dynamically using the CREATE/DROP BACKEND command.
- Frontend — commands for the distributed transaction coordination and results processing by the frontend session.
- Backend — commands for data access and modification on one or many backend workers.

Using this approach would allow to implement even more efficient JIT (Just-In-Time) compilation to machine code in the future, using bytecode as an intermidient representation.
It allows for implementing a highly performant execution pipeline without dealing with complex distributed snapshot issues and avoids multi-versioning (MVCC) altogether. It does not require periodic garbage collection and VACUUM.
The executor plays a crucial role in the system. It is responsible for executing distributed transactions in a deterministic order, implementing Group Commit, and managing write-ahead logging (WAL).
The executor is optimized for pipelining and optimistic execution. New requests will not wait for the Commit event for other ongoing transactions. Instead, the executor creates a dependency graph between transactions and performs Group Abort in case of failure and Group Commit in the likely case of success. One session always becomes Group Commit Leader to drive Group Commit logic.
All transactions always operate on a STRICT SERIALIZABLE level.
The CHECKPOINT operation is used to create data snapshots. It allows scaling this process by running snapshots for a group of backend workers individually in parallel. The checkpoint operation is also responsible for WAL retention.
During restart, the database finds and reads the latest snapshot files in parallel for each backend individually, reducing start time.
Operations such as CREATE INDEX and ALTER TABLE ADD COLUMN are blocking but completely parallel. Each backend worker will create an index for its partitions.
The PRIMARY KEY is mandatory, and currently, it is also used as a partition key.
Amelie supports two types of tables:
- Partitioned (default)
- Shared
Due to the distributed database nature, the way partitioned tables are operated has some limitations. The primary goal is to eliminate distributed round-trips to the backend workers and ideally execute all transaction statements in one goal.
Partitioned tables cannot be directly joined with other partitioned tables, and the same limitation applies to subqueries. Instead, the transaction must use CTE to achieve the same effect.
Amelie treats CTEs as separate statements to combine and execute non-dependable statements in one operation on backend workers. The query planner tries to rewrite queries using CTE whenever it can.
Another efficient way to JOIN partitioned tables is by using shared tables.
The purpose of shared tables is to support efficient parallel JOIN operations with other partitioned tables, where shared tables are used as dictionary tables. However, frequently updating a shared table is less efficient since it requires coordination and exclusive access.
Shared tables can be joined with other shared tables or CTE results without limitations. However, currently, only one partitioned table can be directly joined with shared tables.
The unlogged tables DML will be excluded from WAL (and replication streaming), and the table's data will be saved during the database CHECKPOINT and recovered upon restart from the last checkpoint.
Unlogged tables can provide an additional performance boost for highly volatile tables.
Additionally, RESOLVED columns are a unique feature of Amelie that allows you to specify expressions that will be executed automatically when a primary key constraint is violated to resolve conflicts. Essentially translating INSERT statements into UPSERTS.
Both of those features allow the creation of highly performant partitioned aggregated tables, the values of which are identical to and can replace further SELECT GROUP BY queries.
A special secondary index type for Vectors will be introduced in the future.

- The database works over HTTP and accepts plain-text SQL or JSON
- HTTP API can be used to load data directly without SQL
- Authentication is based on JWT tokens
- JSON is used for results by default
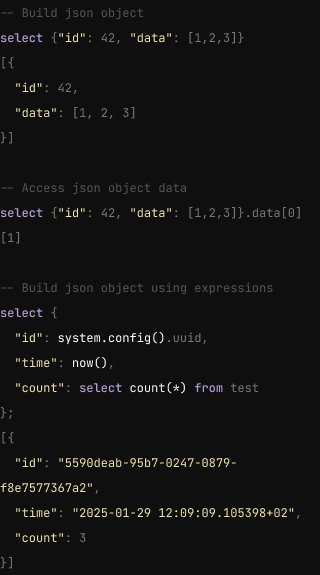
- JSON arrays and objects can be constructed using the [], {} operators
- JSON fields can be accessed directly using the . and [ operators
- JSON columns can store any JSON value (not only object) and is using memory efficient encoding
- Expressions and subqueries can be executed natively inside JSON objects
- Special FORMAT clause can be used to change the Content-Type of results

Lambda expressions can help work with JSON and simplify non-trivial transformations.
Lambda can be used with shared tables, expressions, and subqueries, but it cannot currently be used with partitioned tables on distributed operations (it does not currently support partial state merging).

This works by defining replicas on the Primary server using the CREATE REPLICA statement. Created replica objects are used to identify connecting servers, work as a replication slot to identify replica position, and affect Primary server WAL retention.
Replication is logical and based on WAL streaming. The replica must be created initially from the primary backup and up-to-date with its WALs.
Using any third-party HTTP benchmarking tool configured to generate custom requests is possible.