


Full Parallelization of IO and Compute #
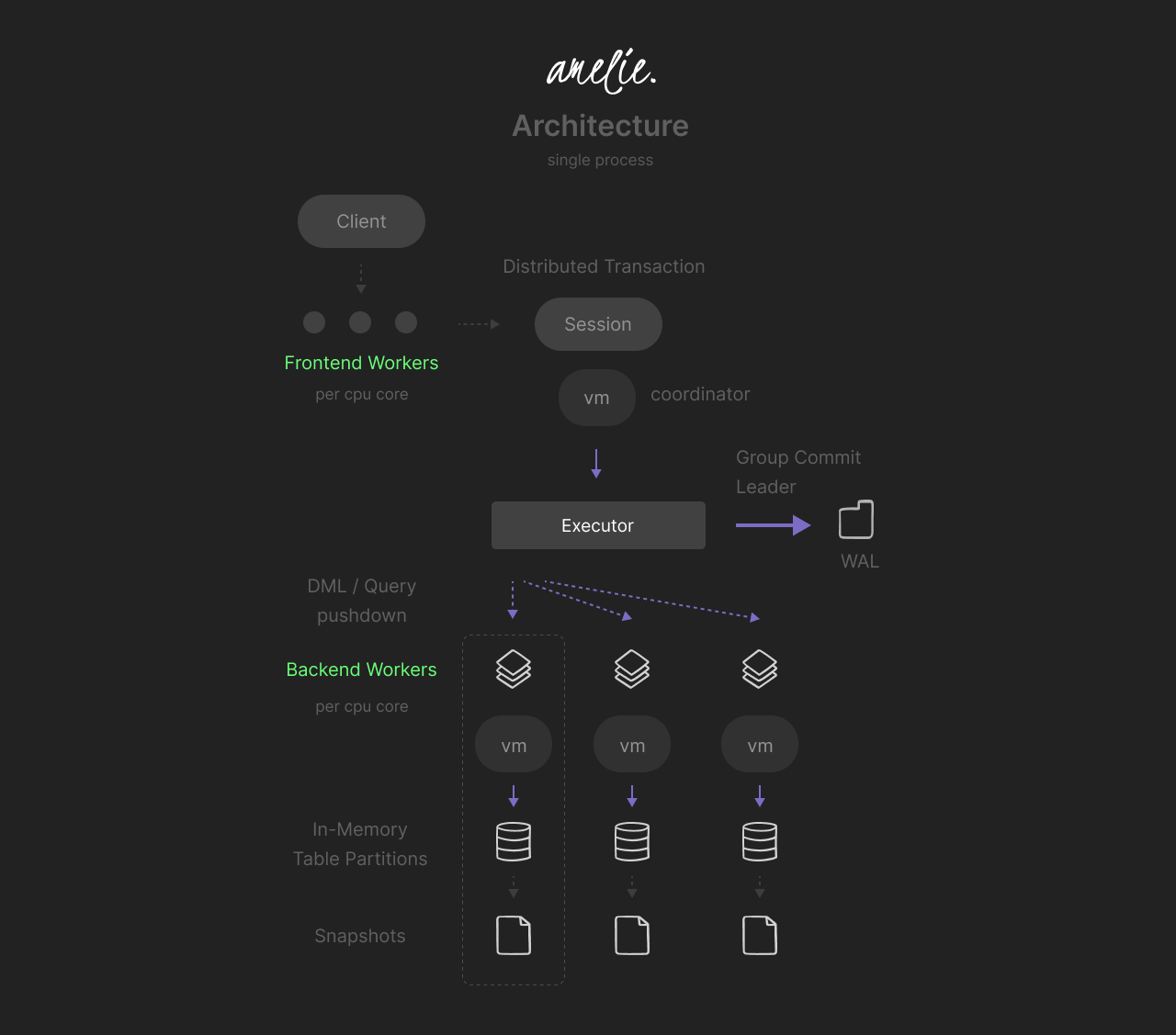
Amelie has a unique architecture for full parallelization and lockless transaction processing. It treats local machine CPU cores as distributed system nodes, sharding, partitioning, and generating parallel group plans for all queries.
While having a distributed database design, Amelie does not require the complex maintenance typical of distributed systems and works as a single process, hiding all the complexity.
Amelie has two independent processing levels for IO and Compute — FRONTEND and BACKEND processing.
During initial repository creation, the number of frontend and backend workers will be set automatically according to the number of CPU cores in the system or configured manually. Backend workers can also be created or dropped dynamically.
The number of worker is the primary factor that affects performance (as well as WAL usage).
Distributed Transactions #
Amelie supports non-interactive deterministic distributed multi-statement ACID transactions.
The Amelie executor executes distributed transactions in a deterministic order, implements GROUP COMMIT,
and manages write-ahead logging (WAL). All transactions always operate on a STRICT SERIALIZABLE level.
The current implementation does not support network-distributed transactions — all distributed transactions are local and executed as part of a single process involving backend worker threads.
Transaction commits only if data is written to WAL first (unless it is configured not to do so).
In case of an error, the transaction will be automatically aborted. An aborted transaction
might also abort other ongoing transactions that happen to be already processed (and not COMMITED) after
the aborted one (see Execution).
Frontend Processing #
The first processing level implements a pool of Frontend worker threads, each of which can handle many clients concurrently.
This is implemented using cooperative multitasking (coroutines) and multithreading.
It separates IO, HTTP/TLS, SQL parsing, Bytecode compilation, and distributed transaction execution coordination from actual data access and modification.
Increasing the worker’s pool size allows the database to serve more clients and increases throughput.
Cooperative Multitasking #
Amelie implements a custom asynchronous multi-threaded coroutine runtime. It handles all system OS aspects, including networking, IPC, and sessions.
Compared to the thread-per-connection approach, it significantly scales processing throughput for short transactions by reducing the number of context switches for multiple connections, allowing more useful work.
Backend Processing #
The second processing level implements a pool of Backend worker threads.
It handles actual data access and modification as part of the distributed transaction driven by the client
session (initiated by one of the Frontend Workers).
A backend worker thread is designed to run in a tight loop with the Executor, sharing a single WAL. Each worker has an associated list of table partitions, which it can access individually without interfering with other workers. Each partition modification is done using the local transaction context.
The worker executes incoming requests in a strict order driven by the Executor. Each request consists of a bytecode explicitly generated for this worker to be executed by its virtual machine context.
Backend workers can be created or dropped dynamically using the CREATE BACKEND and DROP BACKEND commands.
Sharding #
Consistent hashing is used to assign each partition interval on table creation (hash partitioning) and associate them with backend workers. Some requests (like point-lookup DML) will be executed on one worker, and others must be executed on several.
Query Compiler #
After being parsed, each transaction generates two bytecode sections:
- Frontend — commands for the distributed transaction coordination and results processing by the frontend session.
- Backend — commands for data access and modification on one or many backend workers.
Virtual Machine #
A virtual machine interprets bytecode until completion and produces an accessible result. The VM implementation uses an optimized register-based bytecode interpreter, similar to one used in modern programming languages.
Using this approach would allow to implement even more efficient JIT (Just-In-Time) compilation to machine code in the future, using bytecode as an intermidient representation.
Deterministic Executor #
Amelie follows a deterministic transaction processing approach similar to Calvin.
It allows for implementing a highly performant execution pipeline without dealing with complex distributed snapshot issues and avoids multi-versioning (MVCC) altogether. It does not require periodic garbage collection and VACUUM.
The executor plays a crucial role in the system. It is responsible for executing distributed
transactions in a deterministic order, implementing Group Commit, and managing write-ahead
logging (WAL).
The executor is optimized for pipelining and optimistic execution. New requests will not wait for the Commit event for other ongoing transactions. Instead, the executor creates a dependency graph between transactions and performs Group Abort in case of failure and Group Commit in the likely case of success. One session always becomes Group Commit Leader to drive Group Commit logic.
All transactions always operate on a STRICT SERIALIZABLE level.
Partitioned and Shared Tables #
Amelie supports two types of tables: PARTITIONED and SHARED.
By default, all tables are PARTITIONED and distributed. Partitions will be created on each backend worker for
parallel access or modification. Partitioned tables has some limitations.
SHARED tables are not partitioned (single partition) and are available for concurrent direct read access from any backend worker.
The purpose of shared tables is to support efficient Parallel JOIN.
Learn more about the Partitioned and Shared tables.